Use Cases
Encryption At Rest
Why do we need Encryption At Rest?
Apache Kafka® does not directly support any form of encryption for data stored within a broker. This means that the contents of records sent to Apache Kafka are stored in the clear on the broker’s disks. Anyone with sufficient access, such as a Kafka Administrator with file system permissions, is able to read the contents of the records.
This presents a challenge for an enterprise using Kafka to distribute confidential data or PII (Personally Identifiable Information). Enterprises are often subject to confidentiality requirements coming from governmental bodies such as GDPR in the EU or LGPD in Brazil, industry standards such as HIPAA in the health domain or PCI/DSS in the payments domain, in addition to any in-house compliance requirements.
The problem is made more complex if the enterprise has opted to utilise a Cloud Kafka Service as the confidential data is now residing in the clear on the file systems of the service provider.
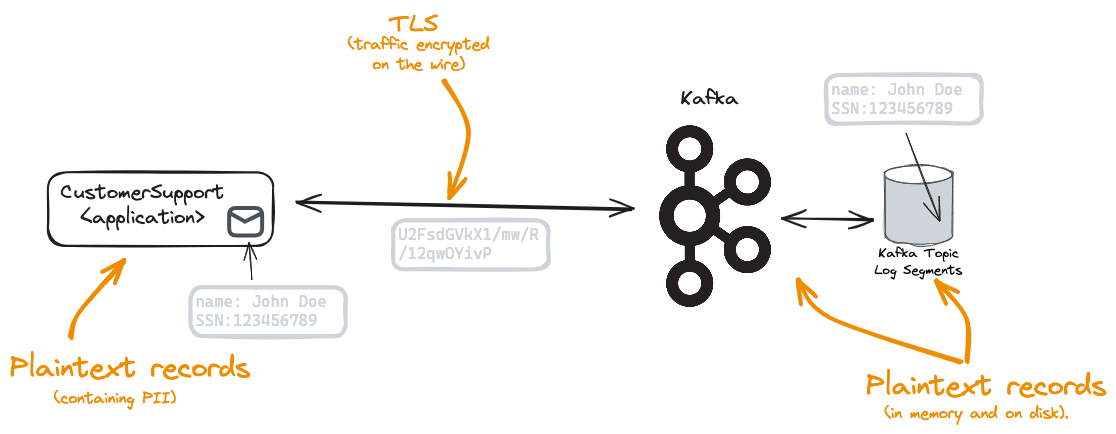 |
|---|
| Problem: Plain text records readable by the Kafka Admins |
Isn’t TLS sufficient?
TLS encrypts the content in transit. It means that someone using a network sniffer cannot intercept what is being sent over the wire between the application and the Kafka Broker. However, once the network packets arrive at the broker, the packets are decrypted and exist in the clear once again. This means the confidential records are in the clear in the memory of the broker and in the clear when the data is written to the file system.
TLS does not change the problem.
Isn’t storage volume encryption an answer?
With storage volume encryption, the contents of the volume are encrypted with a single key. This approach provides some mitigations. If the storage device is stolen or the storage device hijacked and attached to an attacker’s computer, the attacker won’t have the encryption key so won’t be able to read the data, including the Kafka records.
However, there are shortcomings. The encrypted storage volume must be mounted to the computers running the Kafka broker. To do this the and the encryption keys applied at the operating system level. Anybody with shell level access to the hosts is likely to be able to read the data, including the Kafka confidential records.
Storage volume encryption doesn’t really solve the problem.
Can’t the applications encrypt/decrypt the data?
It is possible for producing applications to encrypt data before sending it to Kafka, and for consuming applications to decrypt it again. With this approach the brokers never possess the records in the clear and as they don’t have encryption keys, they cannot decrypt it.
So, this approach does offer a solution to the problem but there are disadvantages.
- Kafka Client libraries don’t support encryption themselves.
- Kafka Client ecosystem is polyglot - it is common to Kafka applications written in many languages (Java, Go, Rust…) deployed within a single organisation. Any solution needs to work across all the target languages.
- There are some encryption libraries for some languages that can be used with the Kafka Clients but these are not available across all languages.
Organisations could write their own encryption code but this is a burden to the application teams. There is a need for interoperability between different language encryption implementations - this increases the overheads. There is also the problem of key distribution to consider. Some part of the system needs to push the correct encryption keys out to the applications and manage tasks such as key rotation. Finally, cryptography is a specialist area and the consequences of a design flaw or bug are significant (confidentiality breach).
Having the applications encrypt/decrypt data themselves, whilst technically feasible, is not really a tenable solution at the scale required for most enterprises.
Kroxylicious Record Encryption
The Kroxylicious Record Encryption feature offers a solution to the problem. The proxy takes the responsibility to encrypt and decrypt the messages. In this way, the Kafka Brokers never see the plain text content of the message thus ensuring confidentiality. Encryption is introduced into the system without requiring changes to either applications or the Kafka Cluster.
Within Kroxylicious, the job of encryption and decryption is delegated to a Kroxylicious Filter. The filter intercepts produce requests from producing applications and encrypts the content, before the produce request is forwarded to the brokers. For consuming, the filter intercepts fetch responses and decrypts the contents before the fetch response is forwarded to the applications.
As the solution is proxy-based, it works regardless of the language the applications is written in.
The solution’s foundations rest on industry-standard encryption techniques.
- Envelope Encryption is employed to efficiently encrypt/decrypt records. Envelope Encryption is specified by NIST SP.-800-57 part 1 revision 5.
- Integrates with common Key Management Services for safe and secure storage of key encryption keys.
- Plugins for HashiCorp Vault® AWS Key Management Service® and Fortanix DSM®
- Additional KMS implementations are planned.
- API available to plug in alternatives
- Uses AES-GCM symmetric keys (in accordance with NIST FIPS 197 and NIST SP 800-38D).
- Supports key rotation1
- Records encrypted using previous key-versions remain decryptable.
Deployment time configuration allows the administrator to choose which encryption keys are to be used to encrypt the records of which topics. Uses cases where some topics are encrypted and some remain unencrypted are supported.
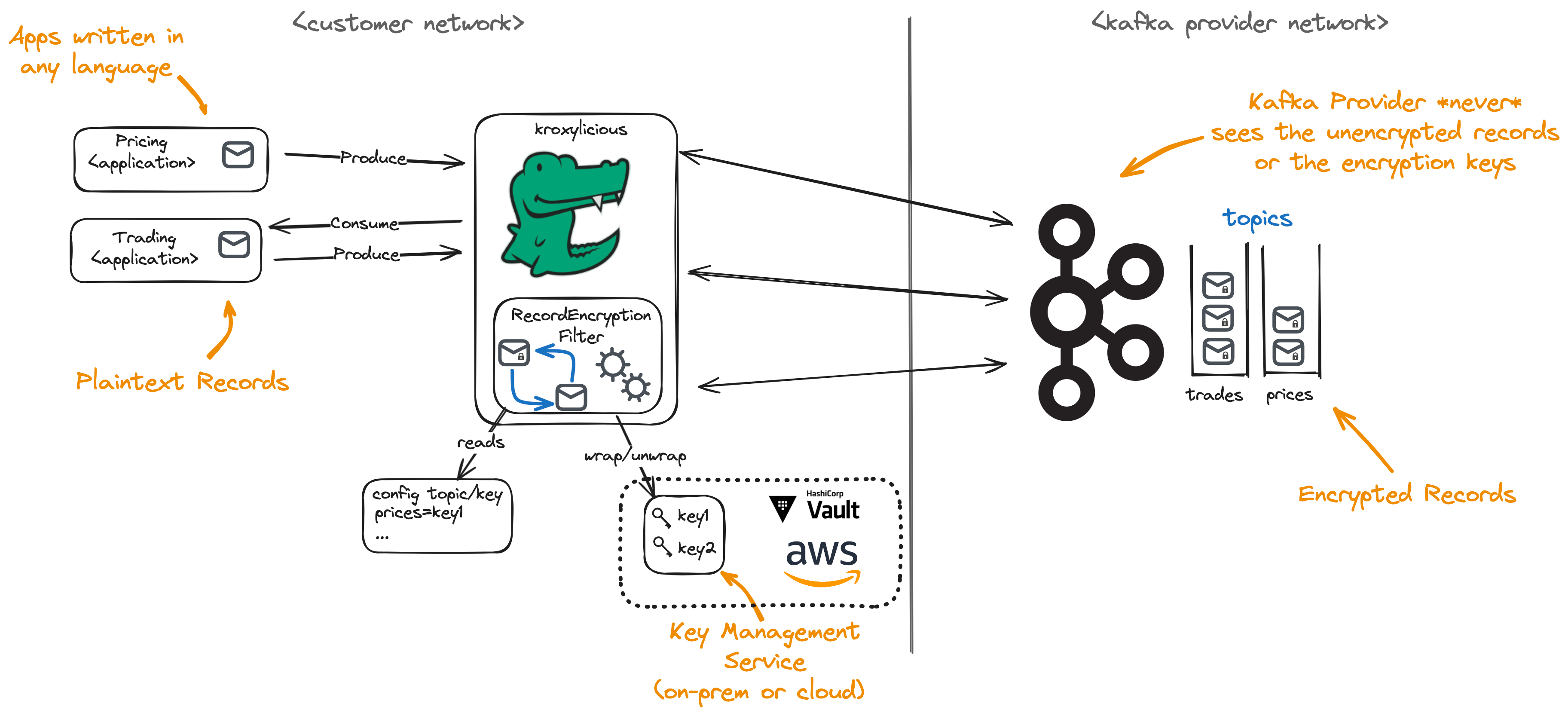 |
|---|
| Kroxylicious Record Encryption Deployment2 |
-
Replacement key material applied to newly produced records only. ↩
-
The Kafka logo is a trademark of The Apache Software Foundation. The Vault mark included in the diagram is a trademark of HashiCorp. The AWS logo is a trademark of Amazon Web Services, Inc. The Fortanix logo is a trademark of Fortanix Inc. ↩
Schema Validation and Enforcement
Why do we need Schema Validation and Enforcement?
In Apache Kafka, producing applications transfer messages to consuming applications. In order for messages to be transferred successfully producers and consumers need to agree on the format of the message being transferred. If there is a mismatch between the format sent by the producer and the expectations of the consumer, problems will result. The consuming application could take the wrong business action or the consuming application may fail to process the message at all, leading to complete failure of the system. This problem is known as a poison message scenario.
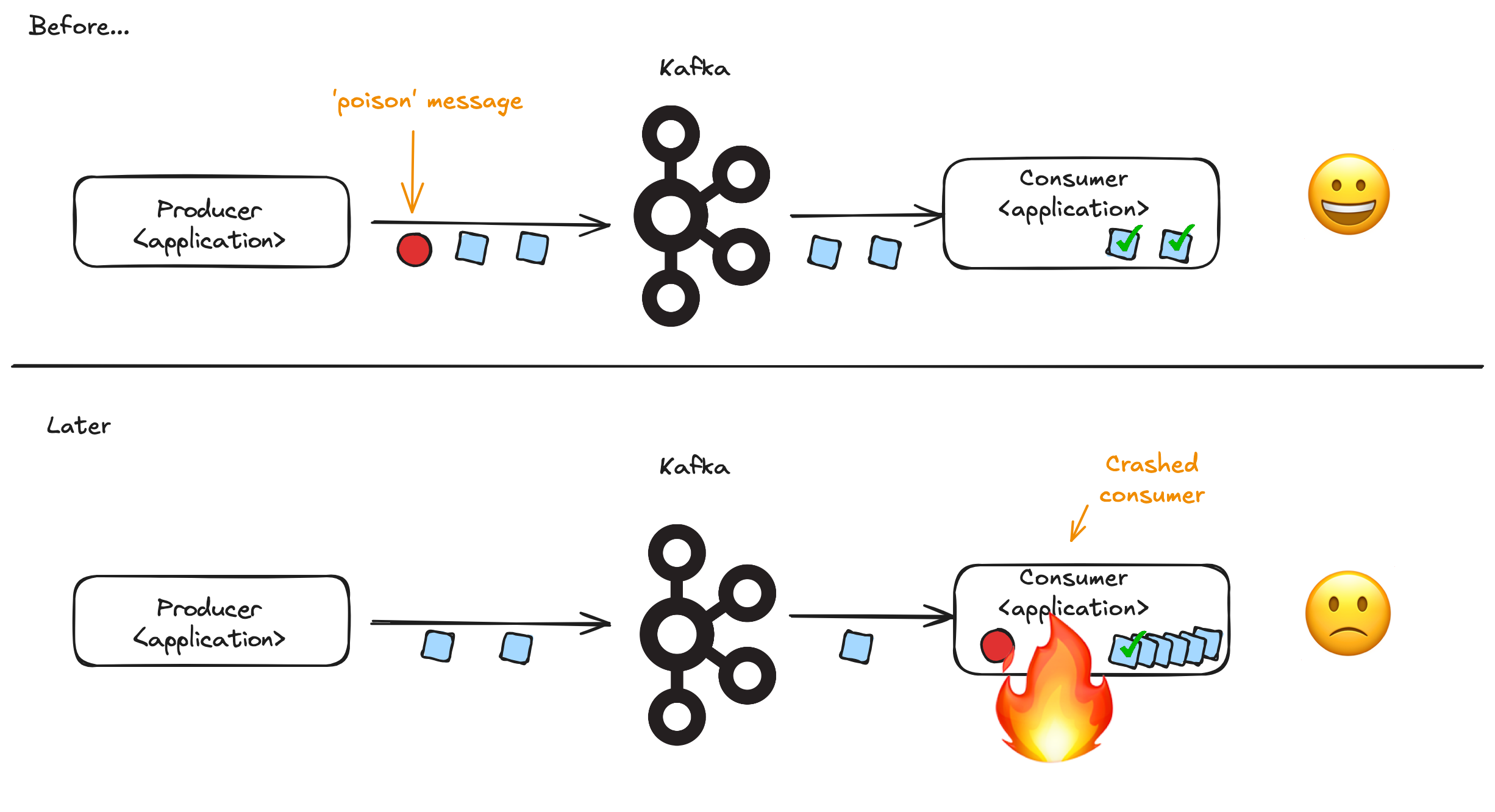 |
|---|
| Problem: Poison message leading to consumer crash |
If there is only a small number of applications, perhaps all managed by the same team, it is possible for the developers to use informal agreements about what message format will be used on which topic. However, as the use of Kafka grows within the organization, the amount of effort required to keep all the formats in agreement grows. Mistakes, and system downtime, become inevitable.
Schemas to the rescue
To overcome the problem, the Kafka client ecosystem supports schemas. Schemas provide a programmatic description of the message format.
Producers use a schema to advertise the format of the messages they send. The consumer uses the same schema to help it decode the incoming message with the certainty that it conforms to the expected format.
The schemas themselves could be packaged as part of the application. Whilst the approach is functional, it is quite inflexible as it means all applications need to be redeployed every time a schema changes. This becomes a challenge as the number of applications in the system grows. To counter this challenge organizations often choose to deploy a Schema Registry.
Schema Registry
The role of the Schema Registry is to maintain a library of schemas that are in-use within an organisation.
Producer applications call the registry to retrieve the schema for the messages they need to send.
Consuming applications use information embedded in the incoming message to be able to retrieve the right schema from the registry. This allows the consumer to decode the message.
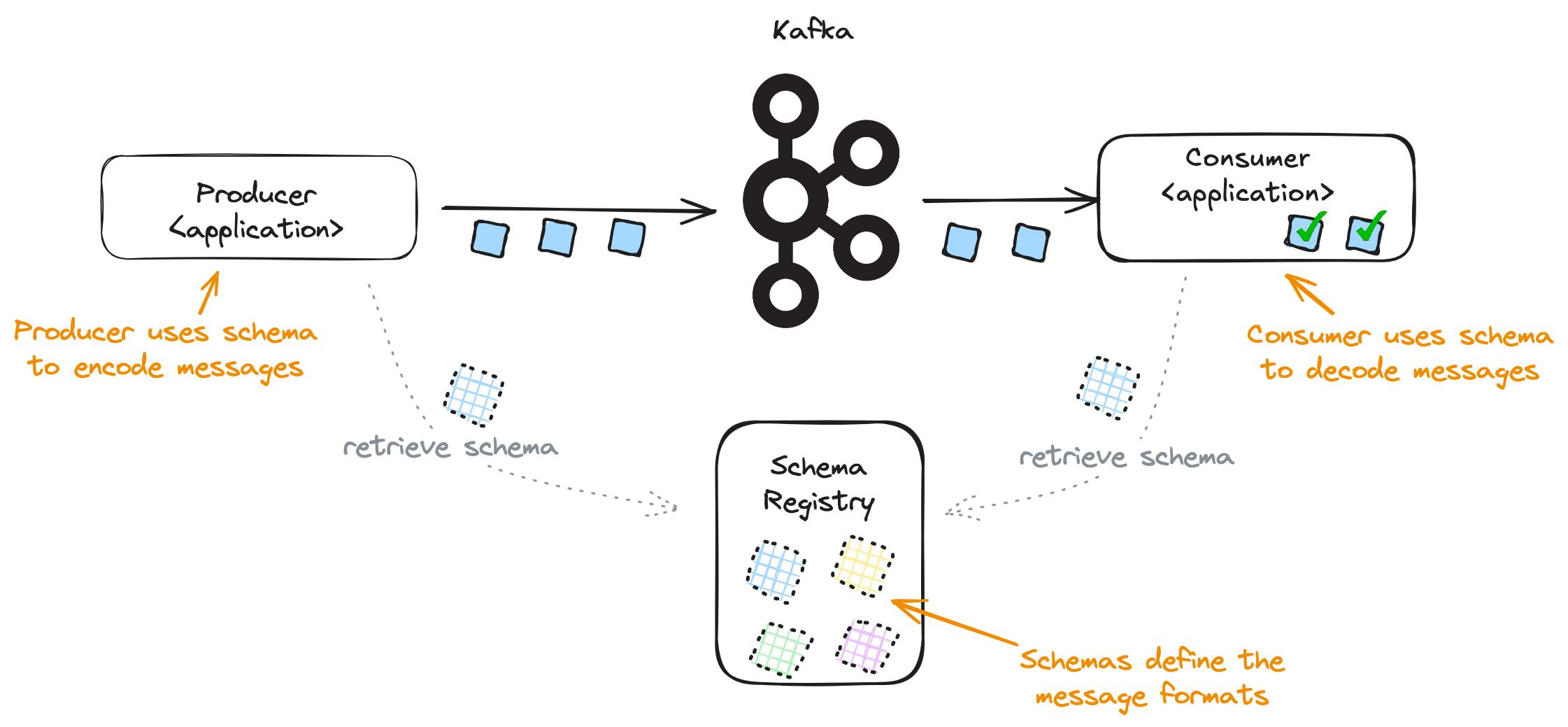 |
|---|
| Kafka applications making use of a Schema Registry |
So, what’s the problem?
If schemas are used correctly across the entire producing and consuming application estate, the potential for a poison message to be introduced into the system is greatly diminished. However, the issue is that there’s significant responsibility on the producing applications to configure and use schemas correctly. There’s nothing in the system to stop, say, a misconfigured producing application using the wrong schema or failing to use schemas at all.
In Kafka, brokers have no knowledge of format of the messages (to the broker, a message is just opaque bytes) and they have no knowledge of the schema. The brokers cannot help us enforce that producing applications use schemas and use them correctly.
Kroxylicious Record Validation
The Kroxylicious Record Validation Filter provides a solution to the problem.
The filter intercepts the produce requests sent from producing applications and subjects them to validation. If the validation fails, the produce request is rejected and the producing application receives an error response. The broker does not receive the rejected records. In this way, one can organize that a poison message never enters the system, even if producing applications are misconfigured.
The filter currently supports two modes of operation:
- Schema validation[^3] validates the content of the record against a schema. Use this for topics which have an entry in the Schema Registry.
- SyntacticallyCorrectJson validation ensures the producer is producing messages that contain syntactically valid JSON. Use for topics which do not have registered schemas.
The following diagram illustrates the filter being used for Schema Enforcement. The filter retrieves the expected schemas from the Schema Registry. Then produce requests are intercepted, and the records subjected to schema validation.
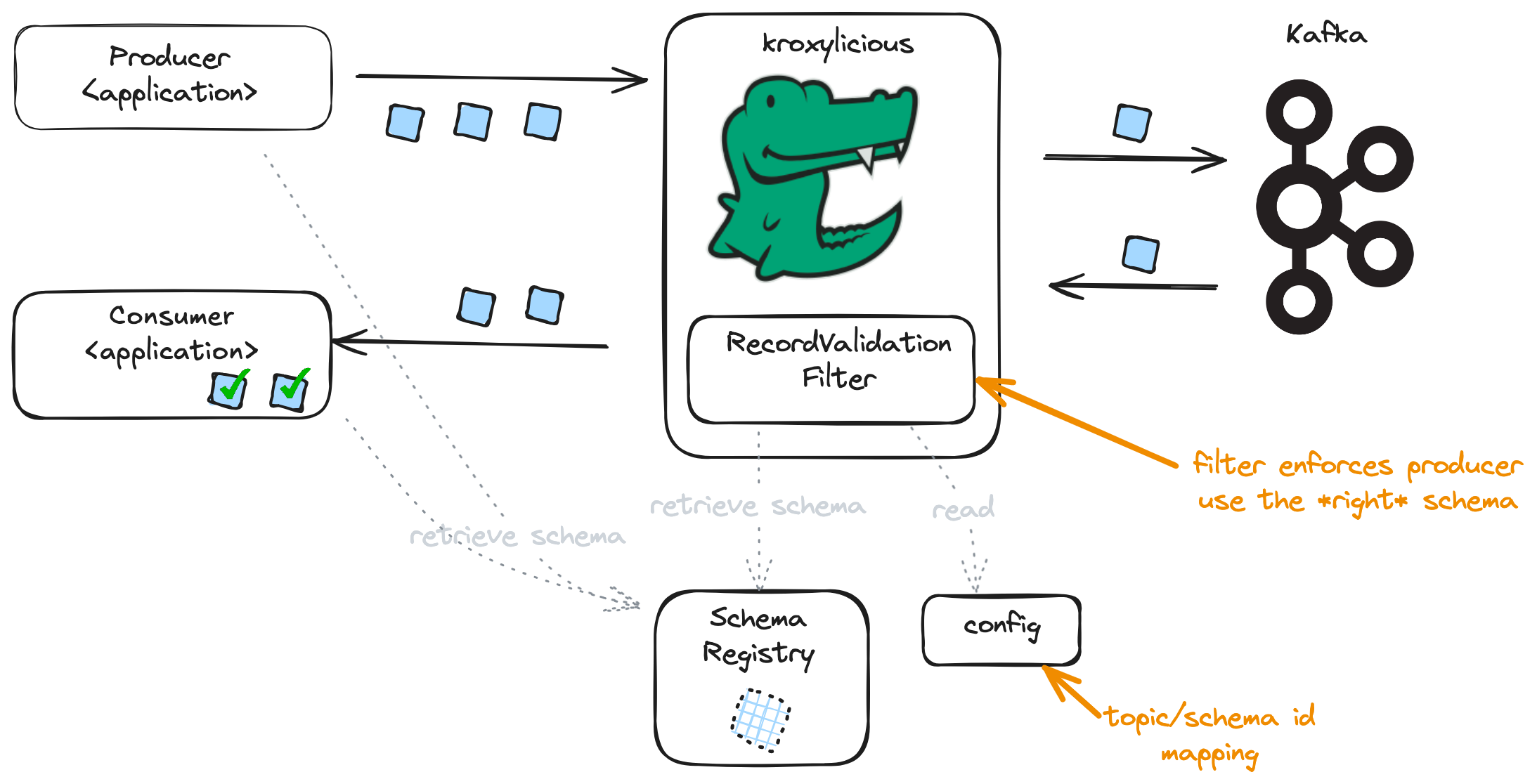 |
|---|
| Proxy configured for schema enforcement |
The following sequence diagram shows how schema validation issues are reported back to the producer.
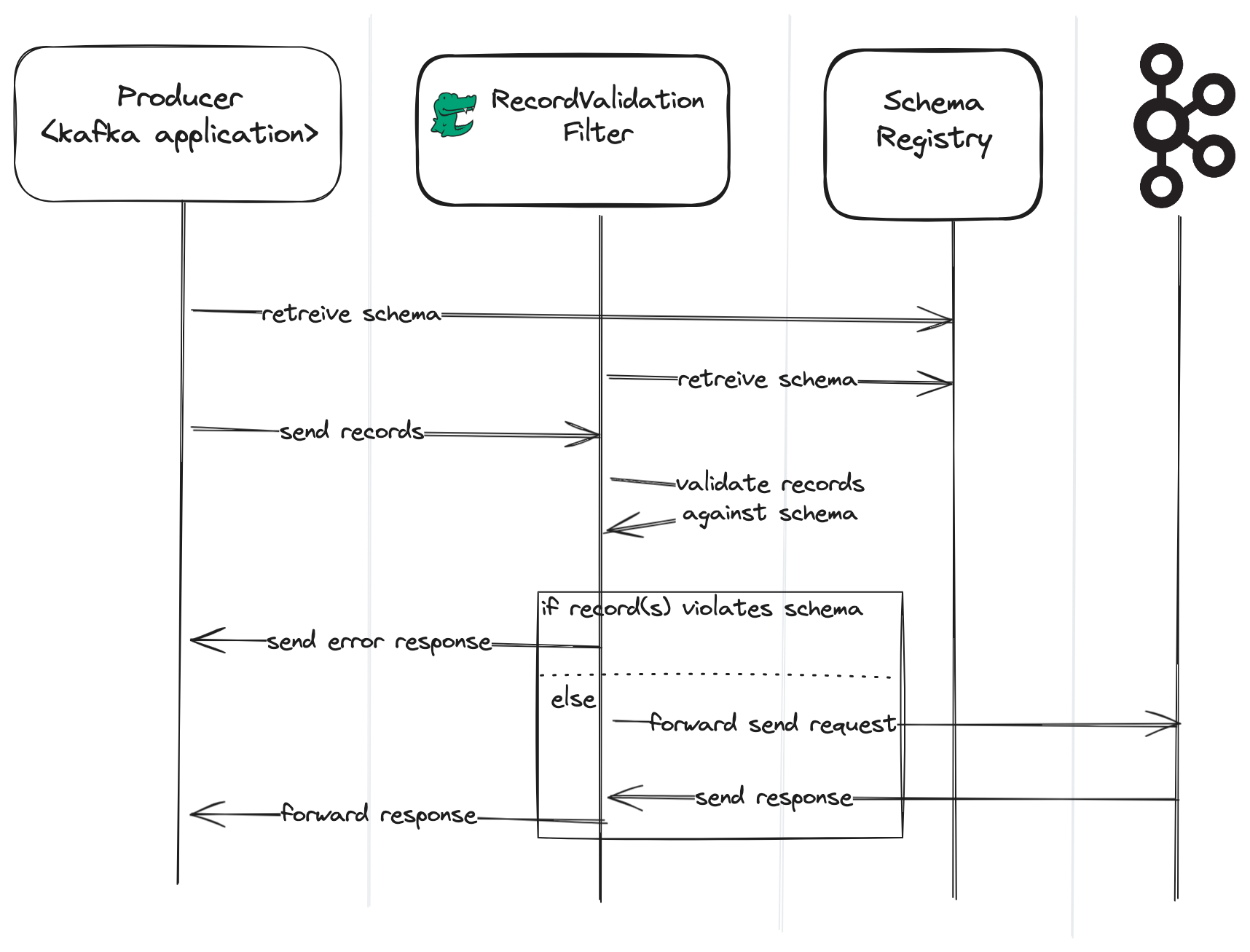 |
|---|
| Sequence diagram highlighting error handling |
The filter accepts configuration that allows you to assign validators on a per-topic basis. There are also configuration options that allow you to define whether the filter rejects just the records that don’t meet the requirements of the validator, or whether then whole batch should be returned.